Язык R в помощь хабра-статисту из песочницы
На написание данной статьи меня сподвиг следующий топик: В поисках идеального поста, или загадки хабра. Дело в том, что после ознакомления с языком R я крайне искоса смотрю на любые попытки, что-то посчитать в экселе. Но надо признать, что и с R я познакомился лишь неделю назад.
Цель: Собрать средствами языка R данные с любимого HabraHabr'а и провести, собственно то, для чего и был создан язык R, а именно: статистический анализ.
Итак, прочтя этот топик вы узнаете:
Ожидается, что читатель достаточно самостоятелен, чтобы самому ознакомиться с основными конструкциями языка. Для этого как никак лучше подойдут ссылки в конце статьи.
Нам понадобятся следующие ресурсы:
После установки вы должны увидеть что-то типа этого:
В правой нижней панели на вкладке Packages вы можете найти список установленных пакетов. Нам понадобится дополнительно установить следующие:
Жмите «Install Packages», выбирайте нужные, а затем выделите их галочкой, чтобы они загрузились в текущее окружение.
Чтобы получить DOM объект документа полученного из интернета достаточно выполнить следующие строчки:
Обратите внимание на передаваемые cookie. Если вы захотите повторить эксперемент, то вам надо будет подставить свои cookie, которые получает ваш браузер после авторизации на сайте. Далее нам надо получить интересующие нас данные, а именно:
Не в даваясь особо в подробности приведу сразу код:
Здесь мы использовали поиск элементов и атрибутов с помощью xpath.
Далее крайне рекомендуется сформировать из полученных данных data.frame — это аналог таблиц базы данных. Можно будет делать запросы разного уровня сложности. Иногда диву даешься, как элегантно можно сделать в R ту или иную вещь.
После формирования data.frame необходимо будет подправить полученные данные: преобразовать строчки в числа, получить реальную дату в нормальном формате и т.д. Делаем это таким образом:
Так же полезно добавить дополнительные поля, которые вычисляются из уже полученных:
Здесь мы всем известные сообщения вида «Всего 35: ↑29 и ↓6» преобразовали в массив данных по тому, сколько вообще было произведено действий, сколько было плюсов и сколько было минусов.
На этом, можно сказать, что все данные получены и преобразованы к готовому для анализа формату. Код выше я оформил в виде функции готовой к использованию. В конце статьи вы сможете найти ссылку на исходник.
Но внимательный читатель уже заметил, что таким образом, мы получили данные лишь для одной страницы, чтобы получить для целого ряда. Чтобы получить данные для целого списка страниц была написана следующая функция:
Здесь мы используем системную функцию Sys.sleep, чтобы не устроить случайно хабраэффект самом хабру:)
Данную функцию предлагается использовать следующим образом:
Таким образом мы скачиваем все страницы с 10 по 100 с паузой в 5 секунд. Страницы до 10 нам не интересны, так как оценки там еще не видны. После нескольких минут ожидания все наши данные находятся в переменной posts. Рекомендую их тут же сохранить, чтобы каждый раз не беспокоить хабр! Делается это таким образом:
А считываем следующим образом:
Ура! Мы научились получать статистические данные с хабра и сохранять их локально для следующего анализа!
Этот раздел я оставлю недосказанным. Предлагаю читателю самому поиграться с данными и получить свои долеко идущие выводы. К примеру, попробуйте проанализировать зависимость настроения плюсующих и минусующих в зависимости от дня недели. Приведу лишь 2 интересных вывода, которые я сделал.
Это видно по следующему графику. Заметьте, на сколько «облако» минусов равномернее и шире, чем разброс плюсов. Корреляция плюсов от количества просмотров значительно сильнее, чем для минусов. Другими словами: плюсуем не думая, а минусуем за дело!
(Прошу прощения за надписи на графиках: пока не разобрался, как выводить их правильно на русском языке)
Это утверждение в упомянутом посте использовалось как данность, но я хотел убедиться в этом в действительности. Для этого достаточно посчитать среднюю долю плюсов к общему количеству действий, тоже самое для минусов и разделить второе на первое. Если бы все было однородно, то множество локальных пиков на гистограмме мы не должны наблюдать, однако они там есть.
Как вы можете заметить, есть выраженные пики в районе 0.1, 0.2 и 0.25. Предлагаю читателю самому найти и «назвать» эти классы.
Хочу заметить, что R богата алгоритмами для кластеризации данных, для аппроксимации, для проверки гипотез и т.п.
Если вы действительно хотите погрузиться в мир R, то рекомендую следующие ссылки. Пожалуйста, поделитесь в комментариях вашими интересными блогами и сайтами на тему R. Есть кто-нибудь пишущий об R на русском?
Считаю, что такие языки как R, haskell, lisp, javascript, python — должен знать каждый уважающий себя программист: если не для работы, то как минимум для расширения кругозора!
P.S. Обещанный исходник
Цель: Собрать средствами языка R данные с любимого HabraHabr'а и провести, собственно то, для чего и был создан язык R, а именно: статистический анализ.
Итак, прочтя этот топик вы узнаете:
- Как можно использовать R для извлечения данных из Web ресурсов
- Как преобразовывать данные для последующего анализа
- Какие ресурсы крайне рекомендуются к прочтению всем желающим познакомиться с R поближе
Ожидается, что читатель достаточно самостоятелен, чтобы самому ознакомиться с основными конструкциями языка. Для этого как никак лучше подойдут ссылки в конце статьи.
Подготовка
Нам понадобятся следующие ресурсы:
После установки вы должны увидеть что-то типа этого:
В правой нижней панели на вкладке Packages вы можете найти список установленных пакетов. Нам понадобится дополнительно установить следующие:
- Rcurl — для работы с сетью. Все кто работал с CURL сразу поймет все открывающиеся возможности.
- XML — пакет для работы с DOM деревом XML документа. Нам понадобится функционал нахождения элементов по xpath
Жмите «Install Packages», выбирайте нужные, а затем выделите их галочкой, чтобы они загрузились в текущее окружение.
Получаем данные
Чтобы получить DOM объект документа полученного из интернета достаточно выполнить следующие строчки:
url<-"http://habrahabr.ru/feed/posts/habred/page10/"
cookie<-"Мои сверхсекретные печеньки"
html<-getURL(url, cookie=cookie)
doc<-htmlParse(html)
Обратите внимание на передаваемые cookie. Если вы захотите повторить эксперемент, то вам надо будет подставить свои cookie, которые получает ваш браузер после авторизации на сайте. Далее нам надо получить интересующие нас данные, а именно:
- Когда запись была опубликована
- Сколько было просмотров
- Сколько человек занесло запись в избранные
- Сколько было нажатий на +1 и -1 (суммарно)
- Сколько было +1 нажатий
- Сколько -1
- Текущий рейтинг
- Количество комментариев
Не в даваясь особо в подробности приведу сразу код:
published<-xpathSApply(doc, "//div[@class='published']", xmlValue)
pageviews<-xpathSApply(doc, "//div[@class='pageviews']", xmlValue)
favs<-xpathSApply(doc, "//div[@class='favs_count']", xmlValue)
scoredetailes<-xpathSApply(doc, "//span[@class='score']", xmlGetAttr, "title")
scores<-xpathSApply(doc, "//span[@class='score']", xmlValue)
comments<-xpathSApply(doc, "//span[@class='all']", xmlValue)
hrefs<-xpathSApply(doc, "//a[@class='post_title']", xmlGetAttr, "href")
Здесь мы использовали поиск элементов и атрибутов с помощью xpath.
Далее крайне рекомендуется сформировать из полученных данных data.frame — это аналог таблиц базы данных. Можно будет делать запросы разного уровня сложности. Иногда диву даешься, как элегантно можно сделать в R ту или иную вещь.
posts<-data.frame(hrefs, published, scoredetailes, scores, pageviews, favs, comments)
После формирования data.frame необходимо будет подправить полученные данные: преобразовать строчки в числа, получить реальную дату в нормальном формате и т.д. Делаем это таким образом:
posts$comments<-as.numeric(as.character(posts$comments))
posts$scores<-as.numeric(as.character(posts$scores))
posts$favs<-as.numeric(as.character(posts$favs))
posts$pageviews<-as.numeric(as.character(posts$pageviews))
posts$published<-sub(" декабря в ","/12/2012 ",as.character(posts$published))
posts$published<-sub(" ноября в ","/11/2012 ",posts$published)
posts$published<-sub(" октября в ","/10/2012 ",posts$published)
posts$published<-sub(" сентября в ","/09/2012 ",posts$published)
posts$published<-sub("^ ","",posts$published)
posts$publishedDate<-as.Date(posts$published, format="%d/%m/%Y %H:%M")
Так же полезно добавить дополнительные поля, которые вычисляются из уже полученных:
scoressplitted<-sapply(strsplit(as.character(posts$scoredetailes), "\\D+", perl=TRUE),unlist)
if(class(scoressplitted)=="matrix" && dim(scoressplitted)[1]==4)
{
scoressplitted<-t(scoressplitted[2:4,])
posts$actions<-as.numeric(as.character(scoressplitted[,1]))
posts$plusactions<-as.numeric(as.character(scoressplitted[,2]))
posts$minusactions<-as.numeric(as.character(scoressplitted[,3]))
}
posts$weekDay<-format(posts$publishedDate, "%A")
Здесь мы всем известные сообщения вида «Всего 35: ↑29 и ↓6» преобразовали в массив данных по тому, сколько вообще было произведено действий, сколько было плюсов и сколько было минусов.
На этом, можно сказать, что все данные получены и преобразованы к готовому для анализа формату. Код выше я оформил в виде функции готовой к использованию. В конце статьи вы сможете найти ссылку на исходник.
Но внимательный читатель уже заметил, что таким образом, мы получили данные лишь для одной страницы, чтобы получить для целого ряда. Чтобы получить данные для целого списка страниц была написана следующая функция:
getPostsForPages<-function(pages, cookie, sleep=0)
{
urls<-paste("http://habrahabr.ru/feed/posts/habred/page", pages, "/", sep="")
ret<-data.frame()
for(url in urls)
{
ret<-rbind(ret, getPosts(url, cookie))
Sys.sleep(sleep)
}
return(ret)
}
Здесь мы используем системную функцию Sys.sleep, чтобы не устроить случайно хабраэффект самом хабру:)
Данную функцию предлагается использовать следующим образом:
posts<-getPostsForPages(10:100, cookie,5)
Таким образом мы скачиваем все страницы с 10 по 100 с паузой в 5 секунд. Страницы до 10 нам не интересны, так как оценки там еще не видны. После нескольких минут ожидания все наши данные находятся в переменной posts. Рекомендую их тут же сохранить, чтобы каждый раз не беспокоить хабр! Делается это таким образом:
write.csv(posts, file="posts.csv")
А считываем следующим образом:
posts<-read.csv("posts.csv")
Ура! Мы научились получать статистические данные с хабра и сохранять их локально для следующего анализа!
Анализ данных
Этот раздел я оставлю недосказанным. Предлагаю читателю самому поиграться с данными и получить свои долеко идущие выводы. К примеру, попробуйте проанализировать зависимость настроения плюсующих и минусующих в зависимости от дня недели. Приведу лишь 2 интересных вывода, которые я сделал.
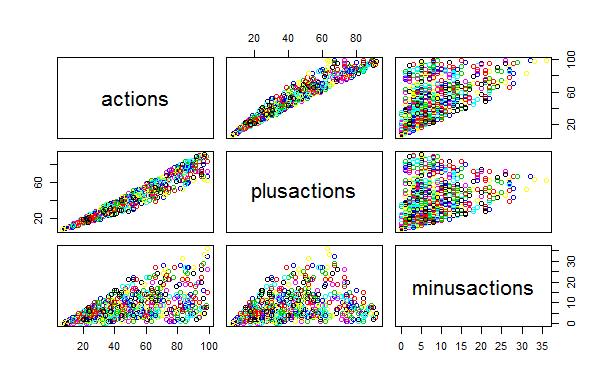
Пользователи хабра значительно охотнее плюсуют, чем минусуют.
Это видно по следующему графику. Заметьте, на сколько «облако» минусов равномернее и шире, чем разброс плюсов. Корреляция плюсов от количества просмотров значительно сильнее, чем для минусов. Другими словами: плюсуем не думая, а минусуем за дело!
(Прошу прощения за надписи на графиках: пока не разобрался, как выводить их правильно на русском языке)
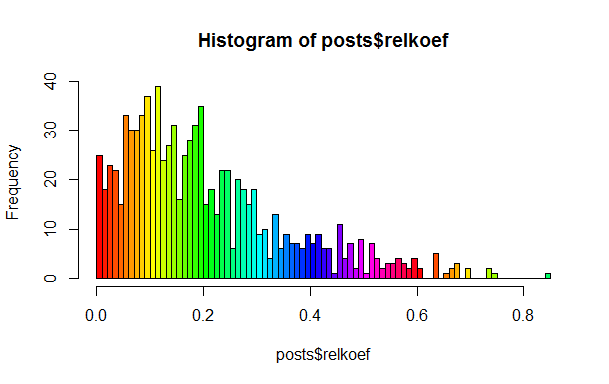
Действительно есть несколько классов постов
Это утверждение в упомянутом посте использовалось как данность, но я хотел убедиться в этом в действительности. Для этого достаточно посчитать среднюю долю плюсов к общему количеству действий, тоже самое для минусов и разделить второе на первое. Если бы все было однородно, то множество локальных пиков на гистограмме мы не должны наблюдать, однако они там есть.
Как вы можете заметить, есть выраженные пики в районе 0.1, 0.2 и 0.25. Предлагаю читателю самому найти и «назвать» эти классы.
Хочу заметить, что R богата алгоритмами для кластеризации данных, для аппроксимации, для проверки гипотез и т.п.
Полезные ресурсы
Если вы действительно хотите погрузиться в мир R, то рекомендую следующие ссылки. Пожалуйста, поделитесь в комментариях вашими интересными блогами и сайтами на тему R. Есть кто-нибудь пишущий об R на русском?
- Бесплатные online курсы на CodeSchool по R
- Курсы на Coursera по анализу данных
- Quick R
- R-bloggers
- is.R()
Считаю, что такие языки как R, haskell, lisp, javascript, python — должен знать каждый уважающий себя программист: если не для работы, то как минимум для расширения кругозора!
P.S. Обещанный исходник
Похожие публикации
Популярность средств веб-аналитики 25 апреля в 16:32
Наиболее популярные системы веб-аналитики в Рунете 28 января в 18:31
Google webmaster — Статистика для автора 3 ноября 2013 в 12:29
Твиттер запустит инструмент для веб-аналитики 14 сентября 2011 в 08:51
В октябре 2011, Google анонсирует Dart: «новый язык для структурного веб программирования» 9 сентября 2011 в 02:57
Веб-аналитика: Не все цифры одинаково полезны 2 августа 2011 в 12:05
Веб-аналитика на КИБоРИФе 15 апреля 2010 в 15:46
Веб-аналитика: анализируй это! Часть 6. Action! 25 декабря 2009 в 13:53
Веб-аналитика: анализируй это! Часть 5. Разделяй и думай 19 октября 2009 в 16:33
Веб-аналитика: анализируй это! Часть 3. Базовые метрики 12 августа 2009 в 20:05
Комментарии (22)